Essayer, tester, échanger les bonnes pratiques, partager les retours d'expériences, ...
toutes nos formations sont disponibles à distance (classes virtuelles) et en centre de formation (présentiel), au choix.
Vous pouvez même changer de modalité en cours de formation, si vous avez des contraintes : par exemple, commencer en présentiel et continuer les jours suivants à distance.
Les outils pédagogiques et l'infrastructure de travaux pratiques mis à disposition sont accessibles depuis nos locaux, ou depuis votre entreprise ou votre lieu de télétravail, à volonté
N'hésitez pas à tester nos formations et nos serious games !

Des fondamentaux du BigData jusqu'à la mise en oeuvre technique destinée aux experts: depuis l'écosystème Hadoop, jusqu'à la sécurisation d'une infrastructure Hadoop
En savoir plus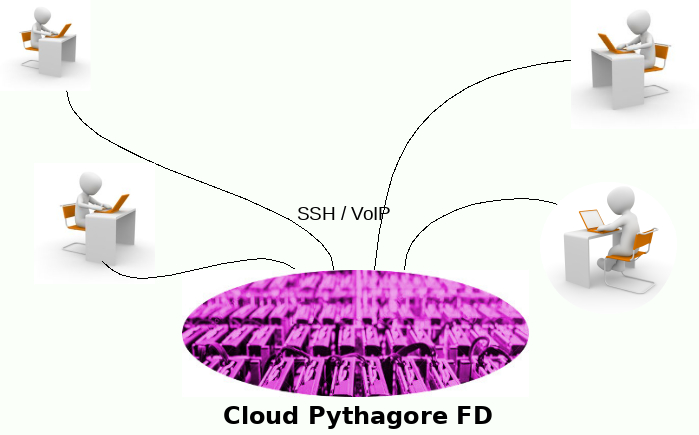
Formations à distance dans un environnement virtuel pour la messagerie, la voix, les TP, le partage de documents...
En savoir plus
Consultez notre calendrier, ou faites-vous faire un programme sur mesure.
Bases de données, langages, réseau, administration, virtualisation... Découvrez ce que nous pouvons faire pour vous !

Mis à disposition des participants pour mettre en pratique tous les concepts abordés (clusters de calcul, baies de stockage distribué, jeux de données pour les tests de performances Cassandra, accès Amazon pour la gestion de ressources dans le cloud, etc ...)
En savoir plusVous souhaitez installer des clusters Hadoop, évaluer les performances de Cassandra sur une infrastructure ad-hoc, tester des calculs Spark sur une grappe Cassandra, etc ... n'hésitez pas !
Le matériel pédagogique mis à disposition des participants lors des formations permet de mettre en pratique tous les concepts abordés (clusters de calcul pour MapReduce, baies de stockage distribué, jeux de données pour les tests de performances Cassandra, accès Amazon pour la gestion de ressources dans le cloud, etc ...)

Nos cursus de formation vont des fondamentaux du BigDatajusqu'à la mise en oeuvre technique destinée aux experts : depuis l'écosystème Hadoop, jusqu'à la sécurisation d'une infrastructure Hadoop, en passant par Cassandra, MongoDB, Spark, les Flux de données avec Storm, etc.
Pour plonger au coeur des technologies BigData, comprendre les concepts de NoSQL, d'indexation, de sharding, ...
Pour savoir concevoir les architectures ad-hoc, intégrer, déployer les solutions, nous proposons une gamme complète de formations, ateliers, classes virtuelles, de l'introduction avec des stages comme "BigData : architecture et technologies", jusqu'à l'expertise sur des sujets comme la "Programmation R sur Hadoop" ou le stage "Machine Learning : technologies et bonnes pratiques"
Pour avoir une vision globale du monde Bigdata, nous proposons également des formations sur les solutions Hadoop comme Configuration d'un système distribué avec Hadoop, ou Développement MapReduce avec Hadoop.
Et, les grands classiques restent toujours à l'affiche : les outils de virtualisation comme kvm, Xen, lxc, ou encore comme les cours sur le cloud Openstack : installation et configuration à l'usage des administrateurs.

À la différence des outils d'auto-formation en e-learning, les classes virtuelles permettent l'interactivité entre les participants et le formateur.
L'innovation apportée par notre solution est la fourniture d'un environnement de travaux pratiques comme dans un véritable centre de formation :chaque participant dispose d'un bureau distant avec un tableau blanc partagé, un accès à l'IRC, un espace de partage de documents, et, surtout, un poste de travaux pratiques sur lequel il peut réaliser les exercices. Le formateur peut également se connecter sur le poste, y effectuer des corrections, ou y déposer des fichiers, etc ...
Cette solution, parfaitement adaptée aux formations techniques permet, par exemple, d'organiser des sessions multi-sites pour des entreprises ou organisations dont le personnel est réparti géographiquement sur plusieurs sites.


 |
La certification qualité a été délivrée par Proneo Certification au titre de la catégorie d'action suivante : ACTIONS DE FORMATION. |